Visualization
This is the documentation for visualization functions.
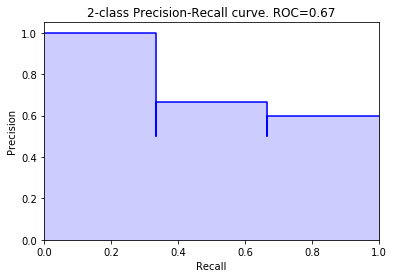
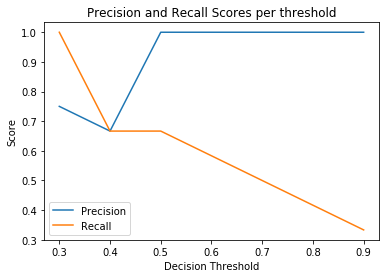
Precision Recall curve plot
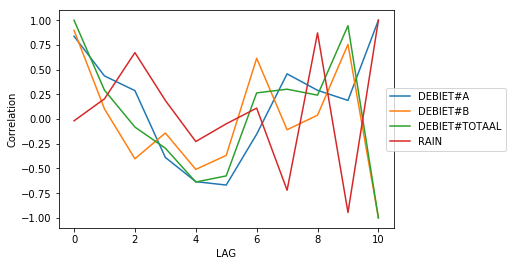
Autocorrelation plot
Threshold curve plot
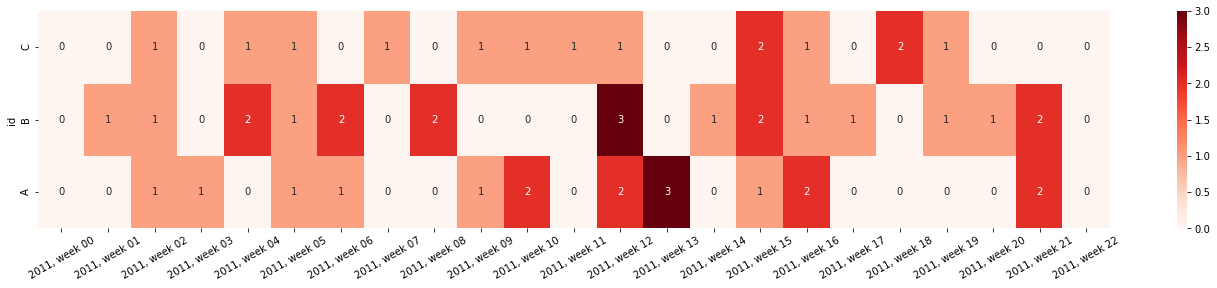
Incident heatmap plot
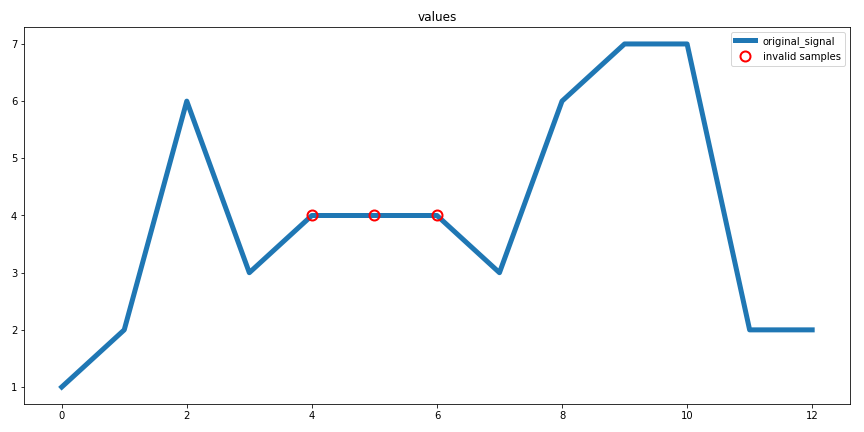
Flatline Removal plot
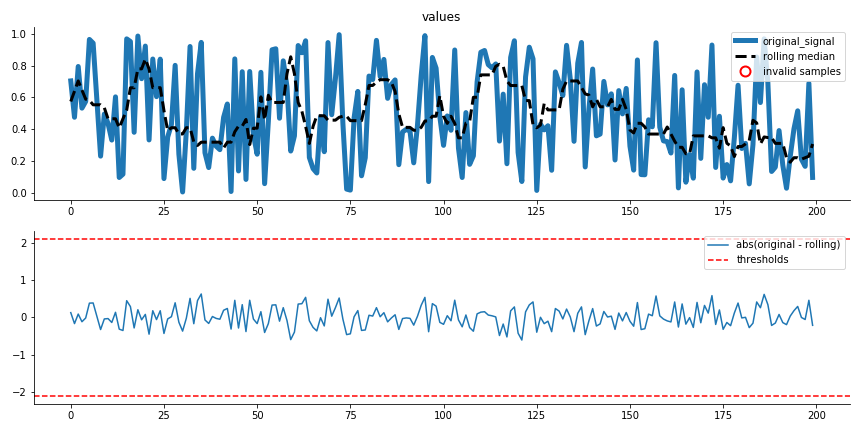
Extreme value removal plot
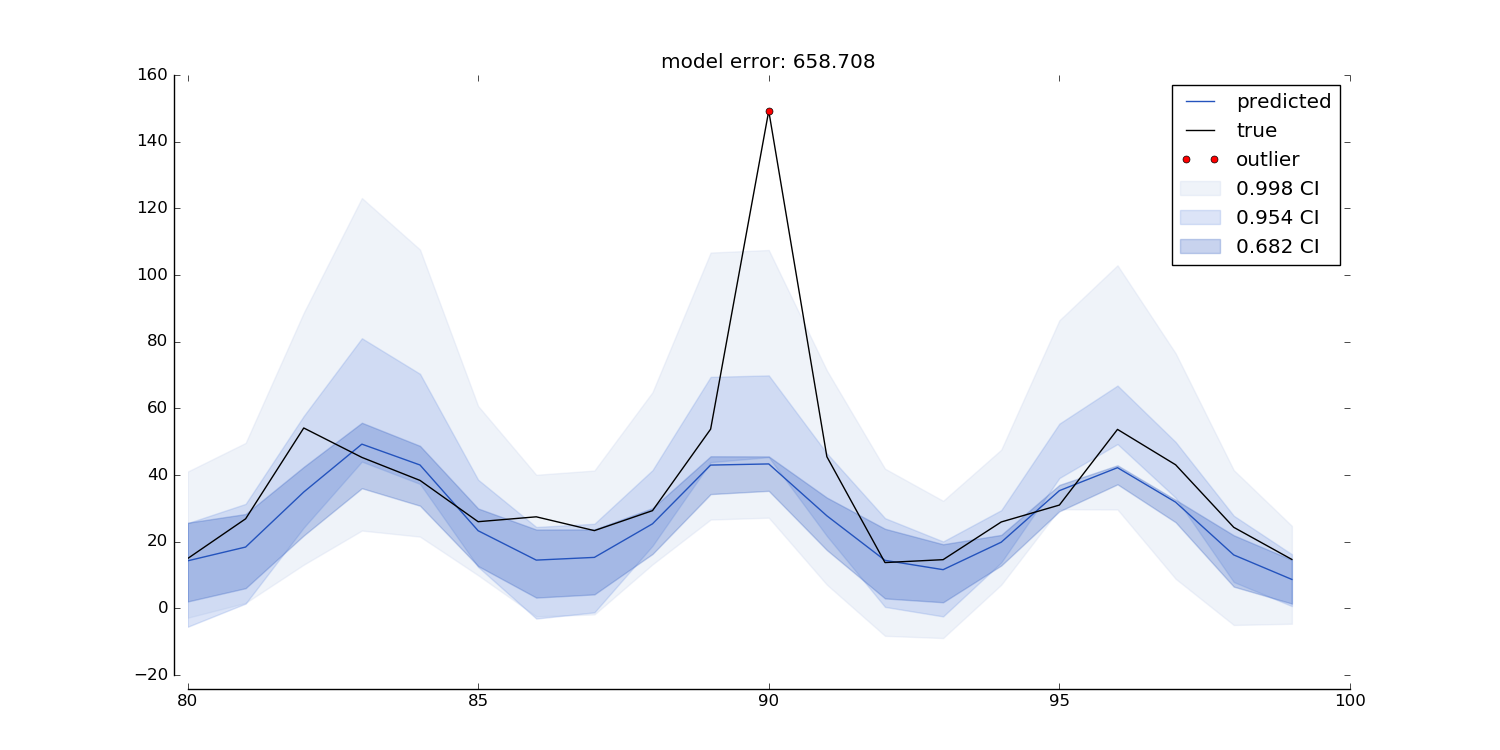
Quantile Regression plot
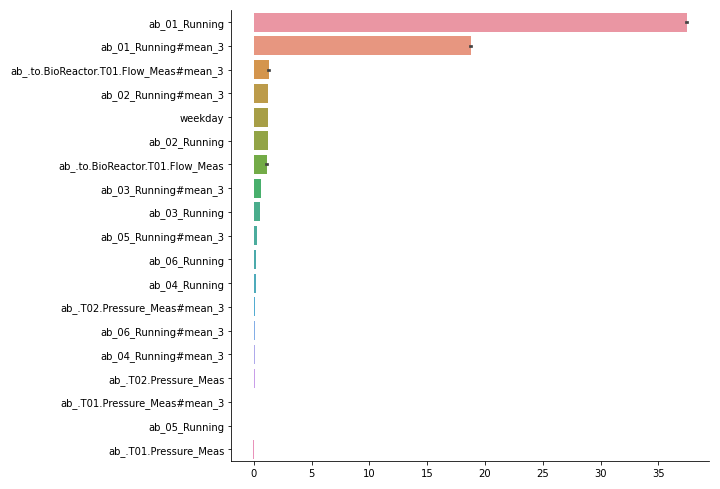
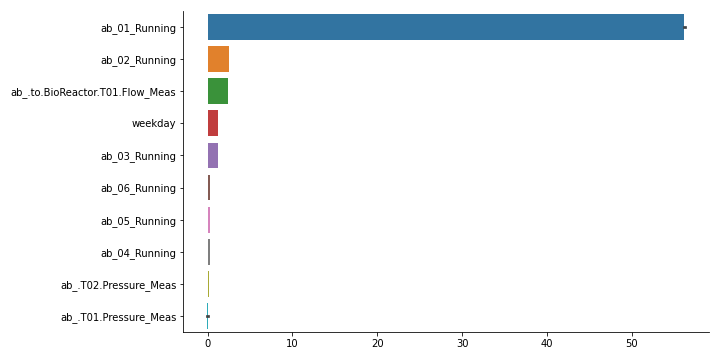
Feature importances plot